Before Kafka

- 소스 앱과 타켓 앱 간 데이터 전송 라인이 매우 많아짐 -> 배포와 장애에 대응하기 어려움
- 프로토콜과 데이터 포맷의 다양화 -> 변경사항 유지보수가 어려움
Kafka Feature

- 소스 앱과 타켓 앱의 결합도를 낮추기 위해 사용
- 카프카 내부에 위치한 각종 토픽(=큐)에 데이터를 넣는 역할은 프로듀서가 수행하고, 데이터를 가져가는 역할은 컨슈머가 수행
- 데이터 흐름에 있어서 서버가 이슈가 생기는 상황에서도 데이터를 손쉽게 복구 가능
토픽
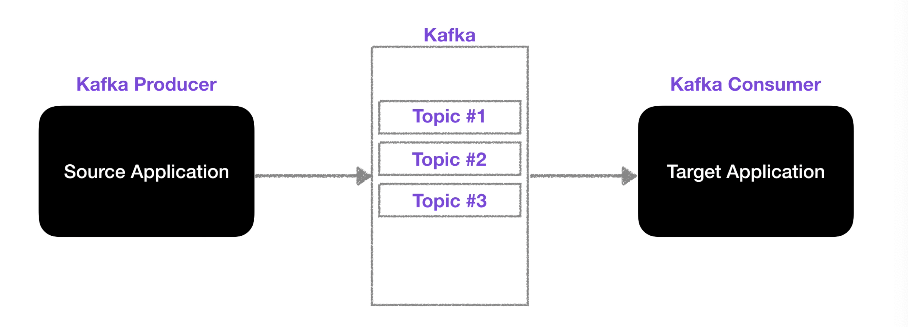
- 카프카에서는 토픽을 여러 개 생성할 수 있음
- 데이터베이스의 테이블이나 파일시스템의 폴더와 유사

파티션이 하나일 경우
- 하나의 큐는 여러 개의 파티션을 가질 수 있고, 하나의 파티션은 큐와 같이 내부에 데이터가 차곡차곡 쌓임
- 컨슈머는 가장 오래된 데이터부터 가져가게 된다. 이때 컨슈머가 데이터를 가져가더라도 데이터는 삭제되지 않음
- 삭제되지 않은 데이터는 새로운 컨슈머 그룹이 나타났을 때 가져갈 수 있음
파티션이 두 개 이상일 경우
- 파티션을 늘리면 컨슈머를 늘려서 데이터 처리를 분산시킬 수 있음
- 파티션에 데이터를 할당할 때 키가 null이고, 기본 파티셔너를 사용할 경우 Round robin으로 할당한다. 만약 키가 있고, 기본 파티셔너를 사용할 경우 키의 해시 값을 구해서 특정 파티션에 할당
- 파티션은 늘릴 수 있지만 줄이는 것은 불가능하므로 신중해야 함
Broker, Replication, ISR(In-Sync-Replication)
Broker
- 카프카가 설치되어 있는 서버 단위(보통 3개 이상 권장)
복제(Replication)

- 파티션의 복제를 뜻하고, 파티션의 고가용성을 위해 사용(특정 브로커가 죽어 파티션이 망가졌을 때 데이터의 복구를 위해)
- 브로커 개수보다 복제 수가 많을 수 없음
- replication이 1이라면 파티션이 1개만 존재한다는 것이고, N(>=2)라면 파티션은 원본 1개와 복제본 N-1개로 존재
- 원본 1개의 파티션은 리더 파티션이라고 부르고, 나머지 파티션은 팔로워 파티션이라고 부름
ISR
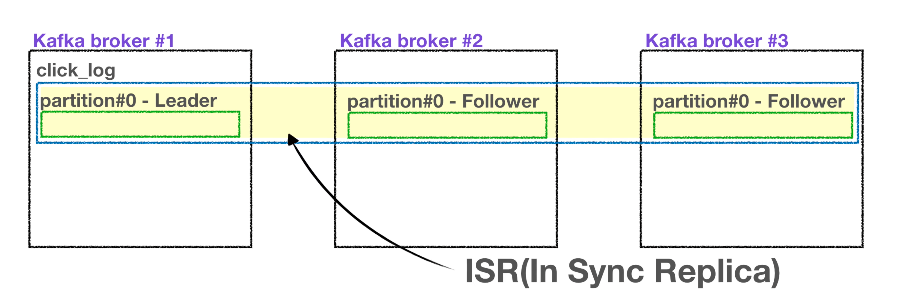
- 리더 파티션과 팔로워 파티션을 ISR이라고 부름
- 리더 파티션은 프로듀서가 토픽의 파티션에 데이터를 전달할 때 전달받는 주체가 됨
Ack
- 프로듀서는 ack라는 상세 옵션을 사용하여 고가용성을 유지
- 0, 1, all 총 세가지 옵션이 존재
0 옵션

- 리더 파티션에 데이터를 전송하고 응답을 받지 않음
- 데이터가 정상적으로 전송되었는지, 나머지 파티션에 데이터가 정상적으로 복제되었는지 알 수 없음
- 속도는 빠르지만 데이터 유실 가능성
1 옵션

- 리더 파티션에 데이터를 전송하고 데이터를 정상적으로 받았는지 응답을 받음
- 다만 나머지 파티션에 데이터가 복제되었는지 알 수 없음 -> 리더 파티션이 있는 브로커가 장애가 데이터 유실 가능성 O
all 옵션

- 리더 파티션에 데이터를 보낸 후 나머지 팔로워 파티션에도 데이터가 저장된 것을 확인하는 절차를 가짐
- 데이터 유실이 없으나 확인하는 부분이 많기 때문에 속도가 느림
Replication Count
- Replication이 고가용성에 중요한 역할을 하지만 너무 많아지면 브로커의 리소스 사용량도 늘어나게 됨
- 3개 이상의 브로커를 사용할 때 Replication을 3으로 설정하는 것을 추천
Partitioner

- 프로듀서가 데이터를 보내면 무조건 파티셔너를 통해 브로커로 데이터가 전송
- 레코드에 포함된 메시지 키나 값을 통해 데이터를 어떤 파티션에 넣을지 결정
- 파티셔너의 기본 값은 UniformStickyPartition으로, 메시지 키가 있을 때와 없을 때 다르게 동작
- 기본 파티셔너 뿐만 아니라 Partitioner 인터페이스를 사용해서 커스텀 파티셔너를 사용할 수 있음
UniformStickyPartition + 메시지 키 O
- 메시지 키를 가진 레코드는 파티셔너에서 특정한 해시값을 생성해서 이를 기준으로 파티션을 생성
- 항상 동일한 파티션에 데이터가 순차적으로 저장되는 것을 보장
UniformStickyPartition + 메시지 키 X
- 메시지 키가 없는 레코드는 라운드 로빈으로 파티션에 적절히 분배되어 들어감
- UniformStickyPartitioner는 프로듀서에서 배치로 모을 수 있는 최대한의 데이터를 모아서 파티션으로 보냄
Consumer Lag
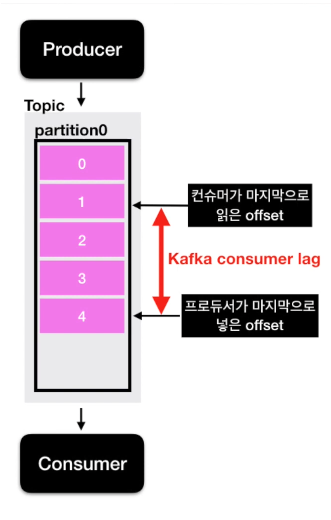
- 파티션에 데이터가 들어가게 되면 각 데이터는 오프셋이라고 하는 숫자가 붙게 됨
- Lag은 프로듀서 오프셋과 컨슈머 오프셋 간의 차이
- 여러 파티션이 존재할 경우 Lag은 여러 개 존재 가능하고, 이중 가장 높은 숫자의 lag을 records-lag-max라고 부름
- 컨슈머의 offset과 프로듀서의 offset을 비교하여 컨슈머의 상태를 체크할 수 있음
Kafka Burrow
Lag을 컨슈머 단에서 수집 및 모니터링
- 컨슈머 로직단에서 lag을 수집하는 것은 컨슈머 상태에 디펜던지가 걸림 -> 컨슈머에 장애가 발생했을 때 더이상 lag을 측정할 수 없음
- lag 정보를 특정 저장소에 저장할 수 있도록 직접 구현해야 함
- 만약 컨슈머 lag을 수집할 수 없는 컨슈머라면 운영이 매우 까다로워 짐
Burrow
- 컨슈머 lag을 효과적으로 모니터링할 수 있도록 지원하는 애플리케이션(Kafka와 독립적임)
- 멀티 카프카 클러스터를 지원 -> 카프카 클러스터들에 붙은 컨슈머의 lag을 모두 모니터링 할 수 있음
- 슬라이딩 윈도우를 통해 컨슈머의 상태를 확인 가능
- warning: 데이터 양이 일시적으로 많아지면서 컨슈머 오프셋이 증가되고 있는 상태
- error: 데이터가 많아지는데 컨슈머가 데이터를 가져가지 않는 상태
- ok: 정상적인 상태
- HTTP api 제공
본 게시글은 데브원영의 아파치 카프카 영상을 바탕으로 작성되었습니다.
'DevOps' 카테고리의 다른 글
| 아파치 카프카 개발 (0) | 2022.01.25 |
|---|---|
| WebSocket vs HTTP (0) | 2022.01.04 |
| 모놀리식 vs 마이크로서비스 아키텍처 (0) | 2021.11.21 |
| CSR / SSR (+ SPA / MPA) (0) | 2021.11.08 |
| 마이크로서비스 아키텍처(MSA) 개념 및 이해 (0) | 2021.11.04 |



댓글